
Mysql索引&B Tree & B+ Tree
MySql数据库InnoDB存储引擎使用的是B+Tree索引。今天把B Tree B+ Tree做个比较。
1、B Tree
在计算机科学中,B树在查找、访问、插入、删除操作上时间复杂度为O(log2~n)(2为底数 n为对数),与自平衡二叉查找树不同的是B树对大块数据读写的操作有更优的性能。
一棵m阶的B树,或为空树,或为满足下列特征的m叉树: ①、树中每个结点至多有m棵子树; ②、若根结点不是终端结点,则至少有2棵子树; ③、除根之外,所有非终端结点至少有棵子树; ④、所有的非终端结点中包含下列信息数据: [n, C0, K0, C1, K1, C2, K2, …., Kn-1, Cn] 其中:Ki[i=0,1,…,n-1]为关键字,且Ki<Ki+1[i=0, 1, …, n-2];Ci[i=0,1,…,n]为至上子树根结点的指针,且指针Ci所指子树中所有结点的关键字均小于Ki[i=0,1,…,n-1],但都大于Ki-1[i=1,…,n-1];
2、B+ Tree
B+树是对B树的一种变形树,它与B树的差异在于:
①有k个子结点的结点必然有k个关键码; ②非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。(也就是B Tree 非叶节点存放的是key、value,B+ Tree非叶节点仅存放key) ③树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
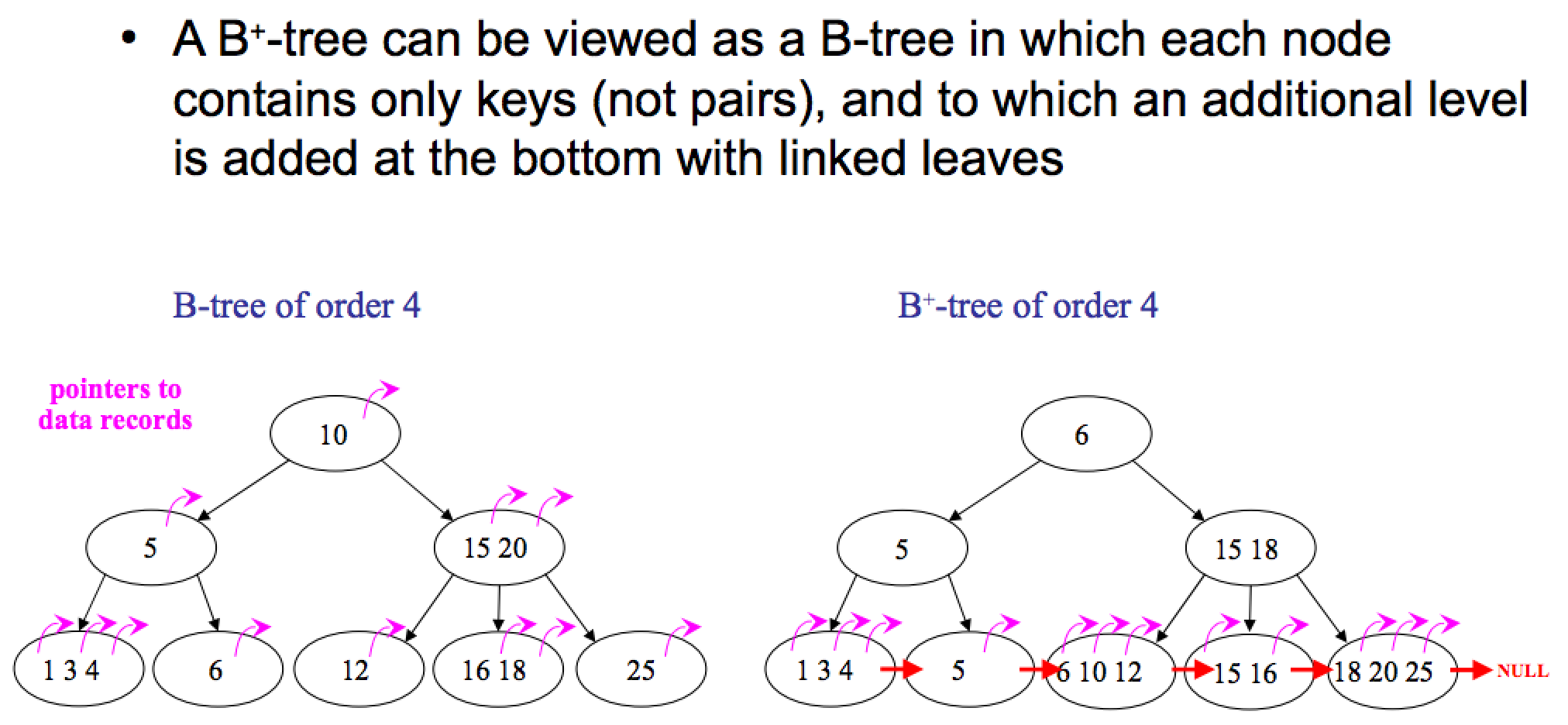
3、比较 B树和B+树各有优缺点:
B+树的磁盘读写代价更低:B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一磁盘页中,那么一页所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。 访问缓存命中率高:其一,B+树在内部节点上不含数据项,因此关键字存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据项也具有更好的缓存命中率;其二,B+树的叶子结点都是相链的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。 B+树的查询效率更加稳定:由于非叶子节点只是充当叶子结点中数据项的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 当然,B树也不是因此就没有优点,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
由于B+树较好的访问性能,一般,B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引!
参考链接: https://stackoverflow.com/questions/870218/differences-between-b-trees-and-b-trees http://www.cnblogs.com/bakari/p/5482594.html 算法导论

